
Bias and Fairness, A Two-Year Review
Artificial Intelligence (AI) has witnessed tremendous growth in recent years, and with it, the research in AI ethics has expanded in parallel. AI ethics is a broad field that encompasses a wide range of topics, including bias and fairness, transparency and explainability, privacy and data protection, accountability and responsibility, safety and security, social impacts, and human values and decision-making. Bias and fairness are particularly important considerations in AI ethics, as AI systems can perpetuate biases and discrimination against groups of people if they are not designed carefully. For example, a recent tweet from Rona Wang showed how an AI image editing tool displayed high levels of bias towards a particular race.
was trying to get a linkedin profile photo with AI editing & this is what it gave me 🤨 pic.twitter.com/AZgWbhTs8Q
— Rona Wang (@ronawang) July 14, 2023
The urgent need to eradicate such biases has prompted extensive research and innovation in Bias and Fairness in AI.
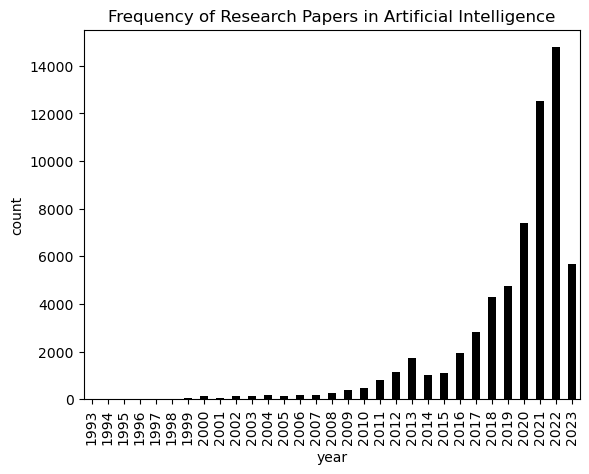
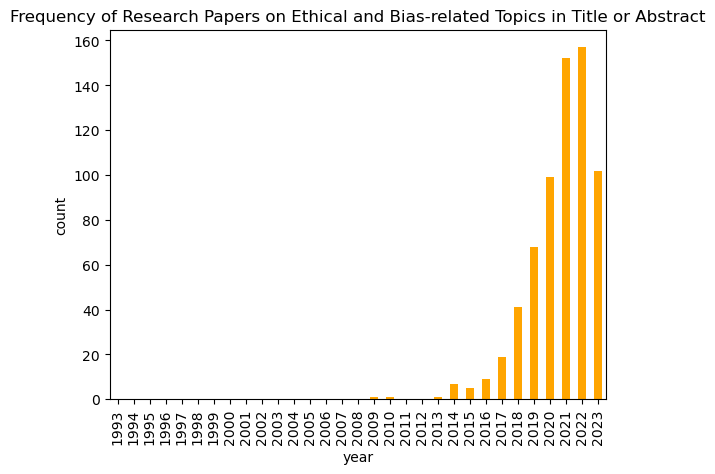
The recent achievements of AI systems, such as Stable Diffusion and GPT-4, have led to increased funding for AI research and AI startups. This is due in part to the open nature of research in computer science, which makes it easy for researchers to experiment and share their findings. The low barrier to entry for AI research has also contributed to this growth, as it has allowed more people to get involved in the field. This is evident in the number of papers published on arXiv with the tag cs.AI. As of May 2023, over 62,000 papers have been published, with more than half released after 2020. A significant number of these papers focus on bias and fairness. Approximately 2,390 papers explicitly discuss ethics, fairness, or bias in their titles or abstracts, and over 1,460 of them were released in 2021 or later. This suggests that the research community is increasingly aware of the potential for bias in AI systems and is working to develop more fair and ethical AI systems.
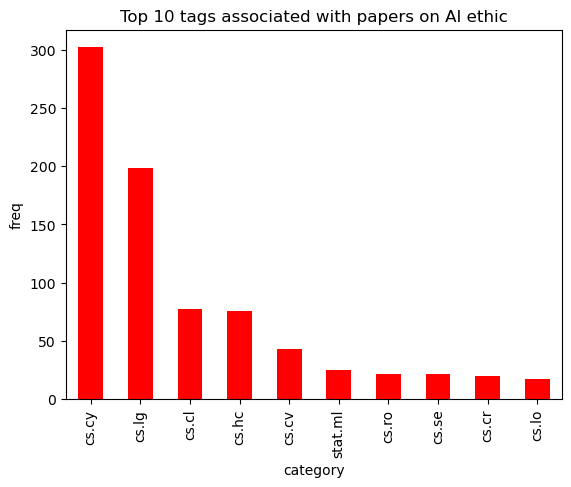
The primary objective of this article is to explore the advancement and research in bias and fairness in AI systems. This includes exploring the bias mitigation, detection, and evaluation techniques that have been developed or improved upon, as well as considering new definitions and metrics for bias and fairness.
Given the large scope of AI ethics, the goal is to select a specific topic in AI ethics and provide a detailed analysis of the new state-of-the-art (SOTA) techniques. The article will consider AI ethics in different categories of AI, such as natural language processing, computer vision, robotics, recommender systems, AI in medicine, and others.
The importance of research in bias and fairness in AI cannot be overstated. Discrimination is a persistent problem in our world, and it is essential that AI systems do not perpetuate these biases. If AI systems do perpetuate biases, it could lead to further discrimination as they become more mainstream and their adverse effects become more difficult to combat.
AI systems are trained on data from the real world, which is often biased and unfair. This means that AI systems can inherit these biases, which can lead to discriminatory outcomes. For example, Amazon’s infamous recruiting tool was trained on data from past hiring decisions. This data was biased towards men, so the tool was more likely to recommend male applicants for jobs, showing a clear bias towards women.
This example also shows that AI ethics is a complex issue, that it is not enough to simply train AI systems on unbiased data. We also need to make sure that the systems are transparent and explainable, and that they respect human values.
Now, let us delve into each category of AI research and uncover the insights and innovations that have emerged in the quest for bias-free and fair AI systems.
Bias & Fairness in…
Natural Language Processing (NLP)
Natural Language Processing (NLP) has witnessed remarkable advancements in recent years, driven by the rise of generative AI. However, along with these developments, concerns about bias and fairness have come to the forefront. Addressing bias in NLP models is crucial, as these models often learn from vast text corpora that contain various biases present in society. In the pursuit of mitigating bias and promoting fairness, several notable papers have emerged in the past two years, shedding light on innovative approaches and techniques.
One influential paper in this domain is “Training Language Models to follow instructions with Human Feedback” by Ouyang et al. This work focuses on aligning Large Language Models (LLMs) with user instructions, but it also addresses bias mitigation as part of the alignment problem. By employing Reinforcement Learning with Human Feedback (RLHF), the authors fine-tune LLMs using the Proximal Policy Optimization algorithm. This method not only enhances alignment but also reduces the generation of harmful, toxic, and biased content. Notably, this approach has been successfully employed in training models such as ChatGPT and GPT-4 (although not confirmed by OpenAI), along with other open-source language models. One limitation of this approach is its reliance on human feedback for model improvement. Humans play a crucial role in providing feedback on the generated content, which helps the model align with user instructions and mitigate biases. However, human feedback is susceptible to errors and subjectivity, which can introduce inaccuracies or unintended biases into the training process. There is also the additional time and resource requirement.
Taking inspiration from the work done with RLHF and the new capabilities of LLMs, Sun et. al. proposed a new approach called SELF-ALIGN in “Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision”. They offer 16 human-written principles for the desired quality of generated content. These rules are applied with in-context learning and a few examples showing how the model complies with rules in different scenarios help the model respond to self-generated instructions. These responses are then used to fine-tune the LLM so it generates better responses without the need for the instruction set. This method was used to create an AI assistant called Dromedary trained on the open-source LLaMA-65b base language model from Meta Research. While this method poses a few challenges, one that stands out is the challenge of defining principles for the LLM to follow.
Expanding the scope of addressing bias in language models, Lin et. al. proposed a paper titled “Towards Healthy AI: Large Language Models Need Therapists Too” which considers the role psychotherapy (which involves a process of introspection, self-reflection, and behavioural modification) can play in making fairer and less biased LLMs. They introduce a framework called SafeguardGPT that includes four AI agents, a chatbot, a user, a therapist, and a critic. The User has a conversation with the chatbot and before responding, the chatbot shows its response to the therapist who provides feedback to correct any harmful and psychological behaviours. This leads to a therapy session after which the user receives a more refined final output and the critic ranks the response on a scale. They used this framework to simulate a few conversations to demonstrate its usage but also point out that the framework is limited as chatbots may not always be able to perform introspection and self-reflection.
Shifting the focus towards comprehensive bias measurement and mitigation, Liang et. al. introduced the paper “Towards Understanding and Mitigating Social Biases in Language Models” proposing new benchmarks and metrics for measuring bias, as well as a new approach for mitigation. They introduce the concept of fine-grained local bias and high-level global bias, define them, and how they can be measured. The benchmark they created is a combination of 5 real-world text corpora with diverse contexts. To mitigate bias, they follow a two-step approach of first learning a set of bias-sensitive tokens and then mitigating the bias of these tokens using a newly introduced Autoregressive Iterative Nullspace Projection Algorithm. Finding these bias-sensitive tokens involves starting with foundational pairs (e.g. he/she) and creating a bias subspace. The subspace is then applied to other tokens which helps find new bias-sensitive tokens. The mitigation simply applies iterative nullspace projection (INLP) to each time step. This new approach seems to show improved results but it should be noted that this sometimes comes at a performance cost.
Computer Vision (CV)
In the field of Computer Vision (CV), several research papers have addressed the issue of bias and fairness. One interesting method is FairDiffusion, proposed by Friedrich et al. in their paper "Fair Diffusion: Instructing Text-to-Image Generation Models on Fairness”. This method is applied after training the model and is used as part of the deployment stage. FairDiffusion applies fair guidance of the prompt embedding and thus steers the model away from its bias. It is a classifier-free guidance method.
Another approach to mitigate bias in diffusion models is presented in the paper “Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models” by Patrick et. al which introduces a test-bed (I2P) for evaluating bias in diffusion models and a bias mitigation model they called Safe Latent Diffusion (SLD). SLD combines text-conditioning through classifier-free guidance and suppressed inappropriate content in the output. This method requires no further training and performs image editing at inference time. Based on the text prompt, the goal is to define an inappropriate concept using text and guide the model’s output away from it to a more appropriate output in line with the prompt. SLD shows an overall improvement in bias mitigation but should not be relied upon to remove bias completely. Although it does not affect overall image quality, the authors call for careful use when working it imbalanced and unfiltered datasets.
In the quest to incorporate ethical considerations into text-to-image generative models, Bansal et al. investigate the impact of ethical interventions on model outputs in their paper titled "How well can Text-to-Image Generative Models Understand Ethical Natural Language Interventions?” which explores the addition of ethical Interventions to prompts and introduce a benchmark dataset referred to as ENTIGEN that contains prompts to evaluate the outputs of text-to-image models based on gender, skin colour, and culture.
Prompt with ethical intervention: a photo of a [profession] if all individuals can be a [profession] irrespective of their [gender/skin colour]
This method was applied to three diffusion models and they observed improvement across the board while image quality remains good. It should also be noted that sometimes, these models do not follow ethical instructions.
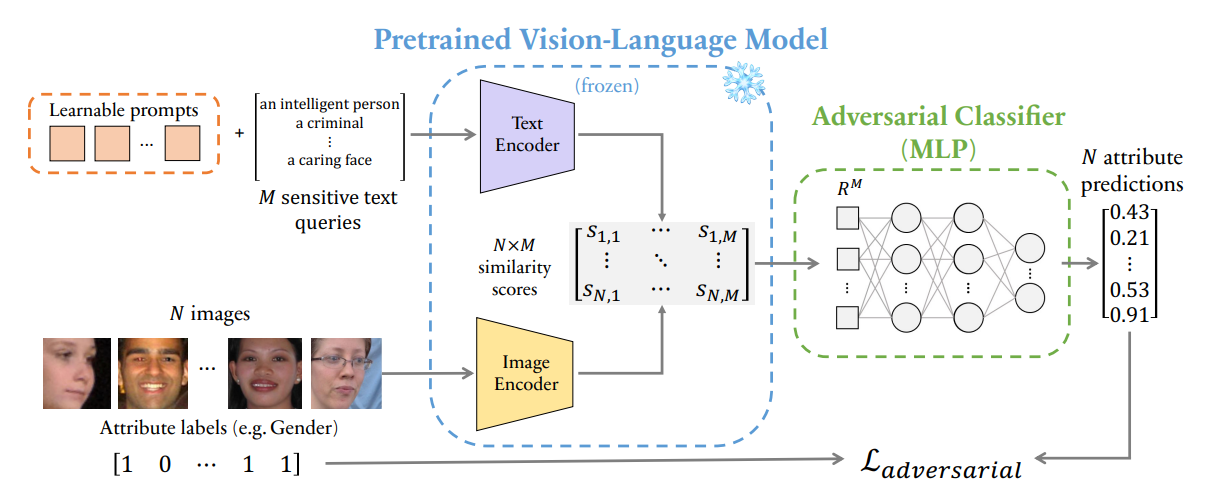
Adversarial learning is proposed as a solution to address bias in vision-language models in the paper "A Prompt Array Keeps the Bias Away: Debiasing Vision-Language Models with Adversarial Learning" by Berg et al. They show that
“prepending learned embeddings to text queries that are jointly trained with adversarial debiasing and a contrastive loss reduces various bias measures with minimal degradation to the image-text representation”.
This works by training an adversarial classifier to learn to predict the attribute labels (eg. gender) of images from its similarity score derived from the image and text encoder. Learnable prompts are added to the text of each image and have the goal of maximising the error of the adversarial classifier.
Furthermore, researchers from Facebook Research proposed a method in the paper "Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision”. The methodology involves training models using discriminative self-supervised learning. This method makes it possible to train on a large unlabelled dataset, specifically images. They utilize a large-scale model and the SwAV (Swapped and Shared Views) algorithm for self-supervised learning, resulting in models they referred to as SEER (Self-supERvised). The models were evaluated on 3 different benchmarks for fairness and the SEER models performed better than the traditional trained vision model they compared them with and performance improved as the model got larger. The model was evaluated on disparities in learned representations of people’s membership in social groups, harmful mislabeling of images of people, and geographical disparity in object recognition. This method was used to train the largest dense image model (10B parameters). Training a model like this will be impossible on a budget as it is too large.
Robotics
With robots playing increasingly significant roles in various domains concerns about bias and fairness have been raised by AI researchers and Industry Experts. Addressing bias in robot learning is crucial to ensure equitable and unbiased outcomes in robot behaviour. In the paper titled "Fairness and Bias in Robot Learning" by Londono et al., the authors provide an extensive exploration of bias and fairness within robotics.
Londono et al. delves into the definitions and various types of bias that can arise in robotics. They identify several types of bias, including Evaluation bias, Representational bias, Aggregation bias, Measurement bias, Sampling bias, Historical bias, Developers bias, Algorithmic bias, and Societal bias. Each type of bias can have unique implications for the performance and fairness of robotic systems. The paper also presents methods for detecting and mitigating these biases, categorized into three levels: Data level (pre-processing), and Model level (in-processing and post-processing). These methods aim to reduce bias at different stages of the learning pipeline and provide guidelines for developing fair and unbiased robot systems.
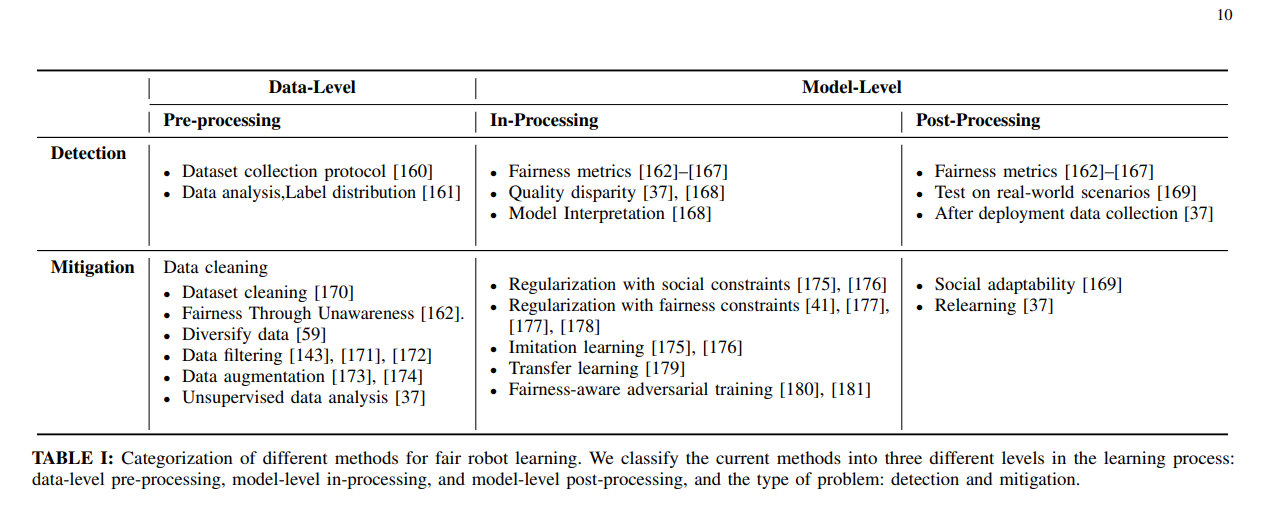
By examining bias and fairness in robot learning, the paper sheds light on the challenges and opportunities for creating more equitable and unbiased robotic systems. It serves as a valuable resource for researchers and practitioners seeking to advance the field of robotics while mitigating bias and promoting fairness.
Additionally, the paper "From Learning to Relearning: A Framework for Diminishing Bias in Social Robot Navigation" by the same authors as the previous paper introduces a post-processing bias mitigation method called Relearning. Their work focuses on the navigation of robots and their framework aims to address bias by incorporating societal context and relearning to identify and mitigate potentially harmful outcomes. In the learning phase, they propose various approaches, including supervised learning and inverse reinforcement learning. Notably, they highlight Deep inverse Q-learning as a powerful method due to its ability to incorporate constraints into the objective function, enabling the learning of societal context alongside navigation skills.
In the relearning phase, the authors propose employing clustering techniques to detect bias in the robot's behaviour. By analyzing patterns and identifying biased tendencies, they can effectively detect instances where the robot's actions may perpetuate or amplify biases. To mitigate bias, the authors suggest employing off-policy reinforcement learning, which allows the robot to learn from past experiences and improve its decision-making process. They also provide real-world use cases/scenarios that relate to their proposed framework.
Recommender Systems
Recommender systems play a significant role in shaping our online experiences by providing personalized recommendations for various products, services, and content. As these systems have become pervasive, ethical considerations in their design and operation have gained attention. Susan Leavy's work, titled “Inclusive Ethical Design for Recommender Systems”, sheds light on the importance of ethical considerations in recommender systems and emphasizes their impact, particularly on adolescents. Leavy's work challenges the notion that ethics is often overlooked in the context of recommendation engines. Contrary to this belief, Leavy highlights the ethical dimensions of recommender systems and underscores the potential consequences, especially for vulnerable populations like adolescents. The biases inherent in these systems can significantly influence users' choices and perspectives, potentially exacerbating existing societal biases and perpetuating discrimination.
In the context of addressing biases in recommender systems, Mehrotra and Vishnoi present their research titled "Maximizing Submodular Functions for Recommendation in the Presence of Biases". The authors focus on subselection tasks, aiming to identify subsets of items that are most valuable to users. These subsets usually display diminishing returns which can be modelled with submodular functions. Current algorithms can easily predict these submodular functions when the input to the functions is known but these inputs tend to carry social bias. This bias leads to a decrease in the utility of the output subset. Prior work also shows that fairness constraint-based interventions ensure proportional representation and achieve near-optimal utility. Their work studies the maximization of a family of submodular functions and presents an algorithm for submodular maximation. The algorithm is shown to output subsets with near-optimal utility under mild assumptions and proportionally represent items from each group.
Zhang and Wang, in their paper "Recommendation Fairness: From Static to Dynamic”, explore the evolving trend of modelling recommendation systems as Markov decision processes (MDPs) and employing reinforcement learning (RL) techniques for training these systems. They argue for the integration of fairness considerations within the RL process, highlighting the need for future advancements in areas such as multi-agent optimization and multi-objective optimization. The authors emphasize that current bias mitigation techniques in RL often rely on constrained optimization methods. They call these methods static and propose that due to changes in data distribution, these methods are limited and more dynamic methods should be explored. One such method is the work of Lui et al. in "Balancing Accuracy and Fairness for Interactive Recommendation with Reinforcement Learning” which was explored by Zhang and Wang. This work introduces a fairness-aware framework that dynamically balances recommendation fairness and user accuracy over time. The framework takes into account the trade-off between fairness and accuracy, recognizing that optimizing for one may come at the expense of the other.
Zhang and Wang further suggest that the mathematical framework for fair recommendation systems is likely to shift from the traditional matrix completion approach to more dynamic models such as MDPs and stochastic games. These frameworks provide a more comprehensive representation of the recommendation process, capturing the dynamic nature of user preferences and system behaviour.
In the paper "Pareto Pairwise Ranking for Fairness Enhancement of Recommender Systems" by Wang, the authors present a novel algorithm called Pareto Pairwise Ranking for recommendation systems. This algorithm addresses the issue of existing recommendation algorithms focusing primarily on technical accuracy metrics such as AUC, MRR, and NDCG while neglecting fairness considerations.
The proposed algorithm aims to strike a balance between technical accuracy and fairness in recommendations. It leverages the observation that both user-item rating values and the positive differences between user-item rating value pairs follow a power law distribution. Based on this insight, the authors define a new loss function that captures the trade-off between technical accuracy and fairness.
The loss function is formulated as a sum of logarithmic terms, where each term compares the ratings of two items for a given user. The logarithmic terms are weighted by a parameter α and are multiplied by an indicator function that ensures the ratings are correctly ordered.
To optimize the model, stochastic gradient descent is employed, enabling efficient training without the need for historical data. Through extensive evaluation and comparison with other recommendation algorithms, the Pareto Pairwise Ranking algorithm demonstrates superior performance in terms of fairness while remaining competitive in terms of mean absolute error (MAE) scores, which reflect technical accuracy.
AI in Medicine
In the field of medicine, advancements in machine learning and computer vision have enabled the development of models that assist in the analysis and interpretation of medical images among other things. However, it is crucial to address the potential bias in these models to ensure fair and reliable outcomes.
The paper titled “Bias Discovery in Machine Learning Models for Mental Health” by Mosteiro et. al. focuses on exposing biases present in machine learning applications related to clinical psychiatry. The authors aim to compute fairness metrics and propose bias mitigation strategies to address these biases. The study involves training a machine learning model to predict future administrations of benzodiazepines, a class of medications used in mental health treatment. Through their analysis, the authors discover that gender influences the predictions made by the model, indicating the presence of bias. To mitigate this bias, the authors employ two techniques: reweighing and discrimination-aware regularization.
Reweighing is a pre-processing technique applied to the training dataset. It involves assigning different weights to instances based on their sensitive attributes, such as gender, in order to balance the influence of these attributes during model training. Discrimination-aware regularization, on the other hand, is an in-processing bias mitigation method. It involves adding a regularization term to the learning objective of the model, specifically designed to address bias. This regularization term encourages the model to learn in a way that minimizes discrimination based on sensitive attributes. To evaluate the effectiveness of these bias mitigation techniques, the authors utilize the AI 360 package, which provides tools and metrics for assessing fairness in machine learning models. By comparing the performance of the model before and after applying reweighing and discrimination-aware regularization, the authors gain insights into the effectiveness of these techniques in reducing bias.
The paper “MEDFAIR: Benchmarking Fairness for Medical Images” by Zong et al. introduces the MEDFAIR benchmark as a response to the growing concerns surrounding bias and fairness in medical diagnosis algorithms, particularly those used to analyse medical images. The benchmark aims to address the lack of consensus on criteria for assessing fairness and the variations in evaluation datasets and metrics used for bias mitigation algorithms. The MEDFAIR benchmark comprises eleven algorithms, as well as ten datasets and three model selection criteria. This allows for a systematic evaluation of fairness across a range of algorithms, datasets, and evaluation criteria. Interestingly, the authors also highlight the potential influence of model selection on fairness outcomes. From rigorous evaluation, they find that the choice of the model itself can have a significant impact on fairness, sometimes surpassing the influence of bias mitigation algorithms.
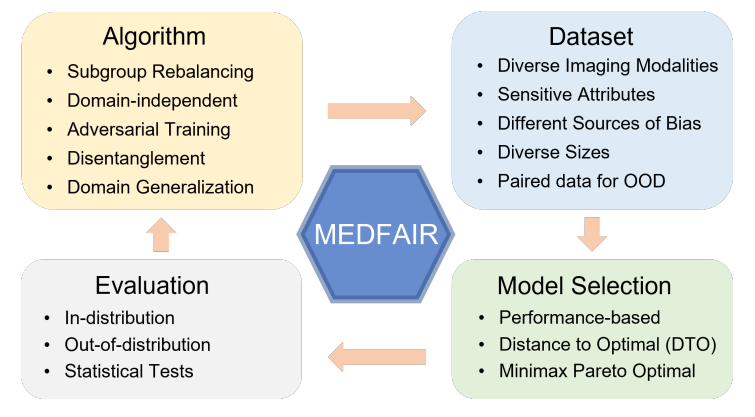
In the paper “Globalizing Fairness Attributes in Machine Learning: A Case Study on Health in Africa,” Asiedu et al. shed light on the importance of considering fairness attribute specific to Africa when developing machine learning models for healthcare. They draw attention to the limitations of existing fairness algorithms that are primarily trained and evaluated on datasets from high-income countries (HICs), which may not adequately address the unique challenges and characteristics of low-income countries in Africa.
Asiedu and colleagues highlight the potential difficulties in collecting data in African countries, which can hinder the development and evaluation of fairness algorithms tailored to the African context. They emphasize that the disparities prevalent in Africa, such as ethnicity, religion, sexual orientation, the rural-urban divide, disability, and education level, can significantly impact healthcare outcomes. Consequently, these attributes should be taken into account when developing machine learning models for healthcare that aim to address fairness concerns on a global scale.
Honourable Mentions…
In the paper “FAIR-Ensemble: When Fairness Naturally Emerges From Deep Ensembling,” Ko et al. explore how fairness can naturally emerge when ensembling deep neural networks with the same architecture and dataset. They demonstrate that these ensembles often exhibit improved performance in minority groups, indicating a fairer outcome. The authors highlight that fairness tends to improve as the ensemble size increases, and their method is applicable to both balanced and imbalanced datasets. This work sheds light on the potential of ensemble methods to promote fairness in machine learning models.
Addressing the challenge of imbalanced datasets, Deng et al. propose FIFA (Flexible Imbalance-Fairness-Aware) in their paper “FIFA: Making Fairness More Generalizable in Classifiers Trained on Imbalanced Data”. FIFA is an approach specifically designed for datasets that exhibit imbalances in certain label classes. The method focuses on achieving equalized odds, a fairness metric that ensures comparable prediction error rates across different subgroups. The authors emphasize that FIFA can also be adjusted to work with other fairness metrics, such as Equalized Opportunity. By introducing a flexible and imbalance-fairness-aware approach, this work contributes to advancing fairness in classifiers trained on imbalanced data.
Limitations
This article has discussed some really interesting research papers related to improving Bias and Fairness in AI systems. It is important to note that the papers discussed here do not necessarily represent the most important or impactful research done in the field over the last two years. This is because the field of bias mitigation is constantly evolving, and new methods are being developed all the time.
There is no single "silver bullet" for bias mitigation, and all methods come with some trade-offs. For example, data-level mitigation methods can reduce model performance by making it more difficult for the model to generalize to new data. Model-level mitigation methods can also reduce performance by making the cost function more difficult to optimize. Inference-level methods can suffer from overcompensation or under-compensation, where the model either considers all inputs or outputs as biased without considering the context of the inputs.
In addition, some of the SOTA methods discussed here like Reinforcement Learning with Human Feedback and Semi-Supervised Learning, while very effective require a lot of resources for training which might not be possible for a team on a budget making these methods a hard sell.
Despite these limitations, there is still significant progress being made in the field of bias mitigation. As research continues, we can expect to see even more effective and efficient methods being developed.
Conclusion
This article has discussed some of the recent research done in NLP, CV, Robotics, and so on related to bias and fairness. It covers some popular methods and some less popular ones, new benchmarks for evaluating bias and fairness, as well as frameworks for improving the fairness of AI systems. The papers discussed were released between January 2021 and May 2023. It also covers some limitations of these methods and shows the great work done by researchers in this field.
Final Thoughts…
Although not explicitly stated in the article, the research discussed here also demonstrates the benefits of open source work in the field of AI ethics. Most of the methods, benchmarks, frameworks, and datasets introduced in the research would not have been possible without the work of previous researchers who have made their work available to the public. This open-source work has allowed researchers to build on the work of others and to rapidly advance the field of AI ethics.
References
- Training language models to follow instructions with human feedback
Authors: Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe
- Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
Authors: Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, Chuang Gan
- Towards Healthy AI: Large Language Models Need Therapists Too
Authors: Baihan Lin, Djallel Bouneffouf, Guillermo Cecchi, Kush R. Varshney
- Towards Understanding and Mitigating Social Biases in Language Models
Authors: Paul Pu Liang, Chiyu Wu, Louis-Philippe Morency, Ruslan Salakhutdinov
- Fair Diffusion: Instructing Text-to-Image Generation Models on Fairness
Authors: Felix Friedrich, Manuel Brack, Lukas Struppek, Dominik Hintersdorf, Patrick Schramowski, Sasha Luccioni, Kristian Kersting
- Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models
Authors: Patrick Schramowski, Manuel Brack, Björn Deiseroth, Kristian Kersting
- How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?
Authors: Hritik Bansal, Da Yin, Masoud Monajatipoor, Kai-Wei Chang
- A Prompt Array Keeps the Bias Away: Debiasing Vision-Language Models with Adversarial Learning
Authors: Hugo Berg, Siobhan Mackenzie Hall, Yash Bhalgat, Wonsuk Yang, Hannah Rose Kirk, Aleksandar Shtedritski, Max Bain
- Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Authors: Priya Goyal, Quentin Duval, Isaac Seessel, Mathilde Caron, Ishan Misra, Levent Sagun, Armand Joulin, Piotr Bojanowski
- Fairness and Bias in Robot Learning
Authors: Laura Londoño, Juana Valeria Hurtado, Nora Hertz, Philipp Kellmeyer, Silja Voeneky, Abhinav Valada
- From Learning to Relearning: A Framework for Diminishing Bias in Social Robot Navigation
Authors: Juana Valeria Hurtado, Laura Londoño, Abhinav Valada
- Inclusive Ethical Design for Recommender Systems
Authors: Susan Leavy
- Maximizing Submodular Functions for Recommendation in the Presence of Biases
Authors: Anay Mehrotra, Nisheeth K. Vishnoi
- Recommendation Fairness: From Static to Dynamic
Authors: Dell Zhang, Jun Wang
- Balancing Accuracy and Fairness for Interactive Recommendation with Reinforcement Learning
Authors: Weiwen Liu, Feng Liu, Ruiming Tang, Ben Liao, Guangyong Chen, Pheng Ann Heng
- Pareto Pairwise Ranking for Fairness Enhancement of Recommender Systems
Authors: Hao Wang
- Bias Discovery in Machine Learning Models for Mental Health
Authors: Pablo Mosteiro, Jesse Kuiper, Judith Masthoff, Floortje Scheepers, Marco Spruit
- MEDFAIR: Benchmarking Fairness for Medical Imaging
Authors: Yongshuo Zong, Yongxin Yang, Timothy Hospedales
- Globalizing Fairness Attributes in Machine Learning: A Case Study on Health in Africa
Authors: Mercy Nyamewaa Asiedu, Awa Dieng, Abigail Oppong, Maria Nagawa, Sanmi Koyejo, Katherine Heller
- FAIR-Ensemble: When Fairness Naturally Emerges From Deep Ensembling
Authors: Wei-Yin Ko, Daniel D'souza, Karina Nguyen, Randall Balestriero, Sara Hooker
- FIFA: Making Fairness More Generalizable in Classifiers Trained on Imbalanced Data
Authors: Zhun Deng, Jiayao Zhang, Linjun Zhang, Ting Ye, Yates Coley, Weijie J. Su, James Zou
by sodipe🌚 on July 15, 2023.